
Guia rápido de pipelines de Big Data: AWS vs. Azure vs. Google Cloud (GCP)
Independentemente da cloud que escolher, otimizar o seu pipeline de dados implica minimizar a sobrecarga de recursos e maximizar a velocidade das consultas. Esta folha de referência é o seu ponto de partida.
Pronto para arquitetar a sua próxima solução de Big Data multi-cloud? A YA INNOVATION LAB é especializada em engenharia de dados agnóstica em relação à cloud e otimização de pipelines. Contacte-nos hoje para rever a sua arquitetura atual e identificar poupanças de custos críticas!
05
Maio


Escolher os serviços cloud certos para construir um pipeline de Big Data escalável e com boa relação custo-benefício é uma das decisões mais críticas para as equipas de dados modernas. Embora cada fornecedor de cloud ofereça um conjunto robusto de ferramentas, os nomes, os padrões de integração e as especialidades diferem significativamente.
Para simplificar o panorama arquitetural, dividimos o ciclo de vida de Big Data em cinco etapas essenciais — da ingestão à visualização — e mapeámos o serviço principal na Amazon Web Services (AWS), Microsoft Azure e Google Cloud Platform (GCP) para cada etapa.
Use esta folha de referência para mapear rapidamente os requisitos do seu pipeline para o serviço cloud ideal, garantindo que constrói um pipeline simultaneamente poderoso e preparado para o futuro.
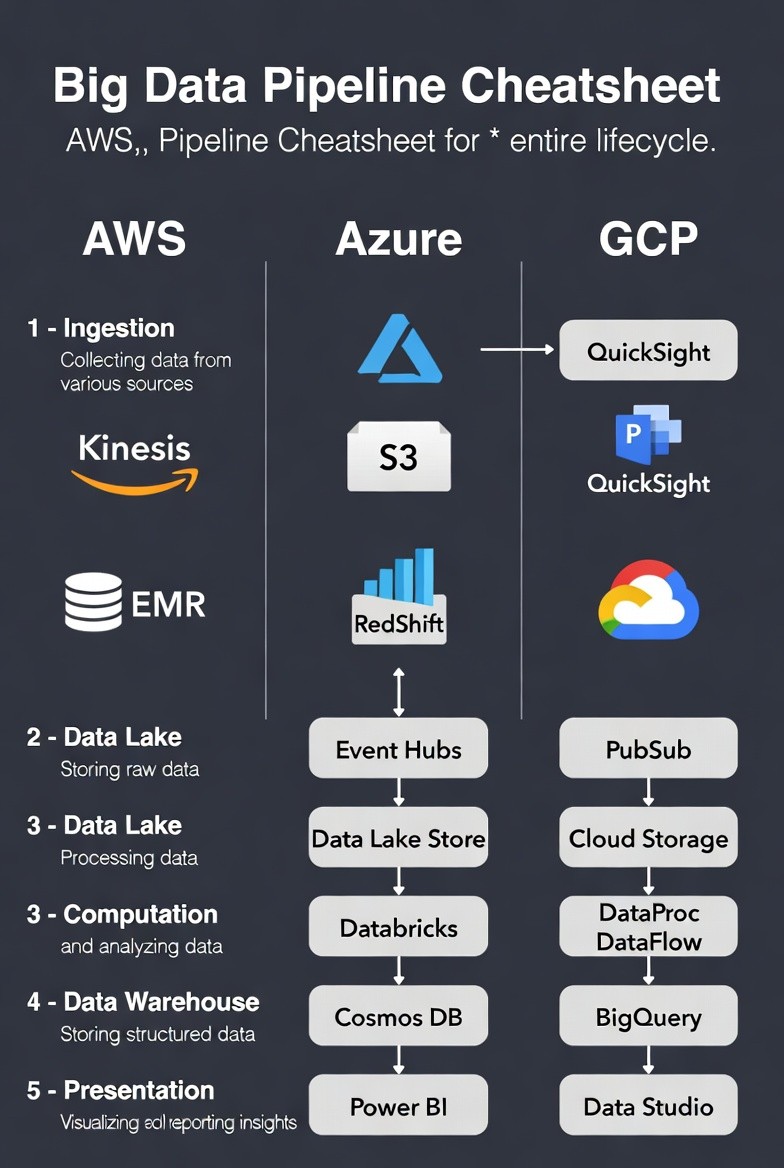
Compreender as 5 Etapas do Pipeline de Big Data
Antes de aprofundar as ferramentas, é essencial definir a função de cada etapa:
Ingestão: Recolha de dados em streaming em tempo real ou de grandes lotes a partir de fontes externas.
Data Lake: Armazenamento de todos os dados brutos, não processados, no seu formato nativo para análise futura.
Computação/Processamento: Transformação, limpeza e análise dos dados brutos (frequentemente com Spark ou serviços especializados).
Data Warehouse: Armazenamento de dados limpos, estruturados, relacionais ou analíticos para consultas rápidas.
Apresentação/BI: Visualização dos insights finais para utilizadores de negócio e reporting
Folha de Referência de Pipeline de Big Data Agnóstica à Cloud
Esta tabela fornece um mapeamento direto de serviço para serviço entre os três principais fornecedores para as necessidades centrais do seu pipeline de Big Data.
Etapa do Pipeline | AWS (Amazon Web Services) | Azure (Microsoft) | GCP (Google Cloud Platform) | Função Principal |
1. Ingestão / Streaming | Kinesis (Data Streams/Firehose) | Event Hubs | Pub/Sub (Publicar/Subscrever) | Recolhe dados em tempo real de várias fontes. |
2. Data Lake / Armazenamento | S3 (Simple Storage Service) | Data Lake Store (ADLS Gen2) | Cloud Storage | Armazena dados brutos e não estruturados de forma económica e flexível. |
3. Computação / Processamento | EMR (Elastic MapReduce) | Databricks (Managed Spark) | DataProc (Managed Spark/Hadoop) & DataFlow (ETL Serverless) | Executa trabalhos de processamento em larga escala (ETL, machine learning). |
4. Data Warehouse / Analítica | RedShift | Cosmos DB (O Synapse Analytics é frequentemente utilizado como data warehouse) | BigQuery | Armazena dados estruturados e limpos, otimizados para consultas analíticas rápidas. |
5. Apresentação / BI | QuickSight | Power BI | Data Studio (Looker Studio) | Visualiza dados e cria relatórios interativos para as partes interessadas. |
Insights Arquiteturais & Principais Diferenças
Embora os serviços listados acima desempenhem a mesma função principal, as suas arquiteturas e modelos de preços oferecem diferenciadores importantes:
1. Serverless vs. Computação Gerida (Etapa 3)
GCP destaca-se com BigQuery (data warehouse serverless) e DataFlow (ETL serverless), eliminando frequentemente a necessidade de gerir clusters.
AWS EMR e Azure Databricks oferecem clusters Spark/Hadoop geridos e poderosos, proporcionando controlo profundo sobre a computação subjacente e sendo frequentemente necessários para lift-and-shift de sistemas legados.
2. Data Warehouses Especializados (Etapa 4)
GCP BigQuery é conhecido pelas suas consultas analíticas incrivelmente rápidas e em escala massiva, bem como por preços baseados na utilização.
AWS RedShift é uma base de dados colunar bem estabelecida, frequentemente otimizada para cargas de trabalho grandes e consistentes.
Azure posiciona frequentemente o Synapse Analytics como a sua plataforma unificada de data warehousing, muitas vezes preferida ao Cosmos DB para data warehousing puramente relacional.
3. Ecossistema de Integração (Etapa 5)
O Power BI da Azure oferece integração incomparável com o ecossistema alargado da Microsoft (Excel, Teams, etc.).
GCP Data Studio foi concebido para ligação fácil a todos os serviços Google, incluindo dados de Sheets e Ads.
AWS QuickSight está a evoluir rapidamente, fornecendo dashboards integrados no ambiente AWS.
Independentemente da cloud que escolher, otimizar o seu pipeline de dados envolve minimizar a sobrecarga de recursos e maximizar a velocidade de consulta. Esta folha de referência é o seu ponto de partida.
Pronto para arquitetar a sua próxima solução de Big Data multi-cloud? A YA INNOVATION LAB é especializada em engenharia de dados agnóstica à cloud e otimização de pipelines. Contacte-nos hoje para rever a sua arquitetura atual e identificar poupanças de custos críticas!

