
The Big Data Pipeline Cheatsheet: AWS vs. Azure vs. Google Cloud (GCP)
No matter which cloud you choose, optimizing your data pipeline involves minimizing resource overhead and maximizing query speed. This cheatsheet is your starting point.
Ready to architect your next multi-cloud Big Data solution? YA INNOVATION LAB specializes in cloud-agnostic data engineering and pipeline optimization. Contact us today to review your current architecture and identify critical cost savings!
05
May


Choosing the right cloud services to build a scalable and cost-effective Big Data pipeline is one of the most critical decisions facing modern data teams. While each cloud provider offers a robust set of tools, the names, integration patterns, and specialties differ significantly.
To simplify the architectural landscape, we've broken down the Big Data lifecycle into five essential stages—from ingestion to visualization—and mapped the primary service on Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) for each stage.
Use this cheatsheet to quickly map your pipeline requirements to the ideal cloud service, ensuring you build a pipeline that is both powerful and future-proof.
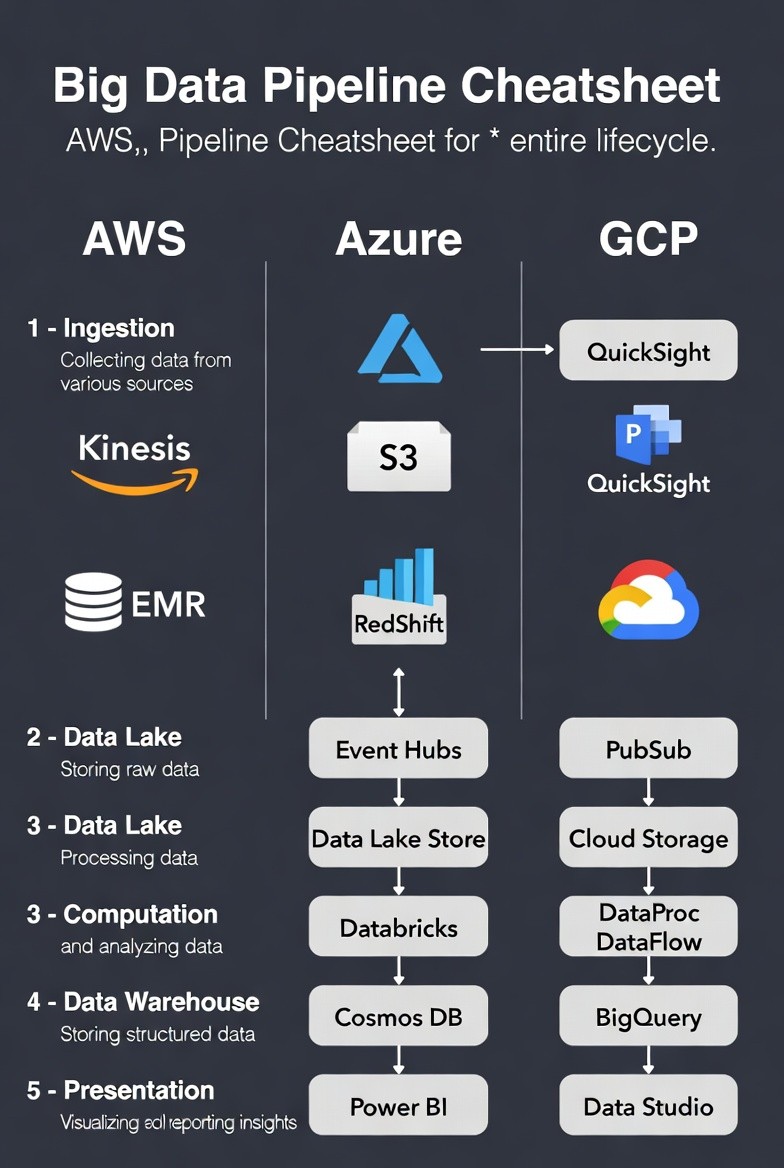
Understanding the 5 Stages of the Big Data Pipeline
Before diving into the tools, it's essential to define the function of each stage:
Ingestion: Collecting real-time streaming data or large batches from external sources.
Data Lake: Storing all raw, un-processed data in its native format for future analysis.
Computation/Processing: Transforming, cleansing, and analyzing the raw data (often using Spark or specialized services).
Data Warehouse: Storing cleaned, structured, relational, or analytical data for fast querying.
Presentation/BI: Visualizing the final insights for business users and reporting
Cloud-Agnostic Big Data Pipeline Cheatsheet
This table provides a direct service-to-service mapping across the three major providers for your core Big Data pipeline needs.
Pipeline Stage | AWS (Amazon Web Services) | Azure (Microsoft) | GCP (Google Cloud Platform) | Core Function |
1. Ingestion / Streaming | Kinesis (Data Streams/Firehose) | Event Hubs | Pub/Sub (Publish/Subscribe) | Collects data in real-time from various sources. |
2. Data Lake / Storage | S3 (Simple Storage Service) | Data Lake Store (ADLS Gen2) | Cloud Storage | Stores raw, unstructured data cheaply and flexibly. |
3. Computation / Processing | EMR (Elastic MapReduce) | Databricks (Managed Spark) | DataProc (Managed Spark/Hadoop) & DataFlow (Serverless ETL) | Runs large-scale processing jobs (ETL, machine learning). |
4. Data Warehouse / Analytics | RedShift | Cosmos DB (Often Synapse Analytics is used as the warehouse) | BigQuery | Stores structured, cleaned data optimized for fast analytical queries. |
5. Presentation / BI | QuickSight | Power BI | Data Studio (Looker Studio) | Visualizes data and creates interactive reports for stakeholders. |
Architectural Insights & Key Differences
While the services listed above perform the same core function, their architectures and pricing models offer key differentiators:
1. Serverless vs. Managed Compute (Stage 3)
GCP excels with BigQuery (serverless data warehouse) and DataFlow (serverless ETL), often eliminating the need to manage clusters.
AWS EMR and Azure Databricks offer powerful, managed Spark/Hadoop clusters, giving deep control over the underlying compute and often necessary for lift-and-shift of legacy systems.
2. Specialized Warehouses (Stage 4)
GCP BigQuery is known for its incredibly fast, massive-scale analytical queries and usage-based pricing.
AWS RedShift is a well-established, columnar database often optimized for large, consistent workloads.
Azure frequently positions Synapse Analytics as its unified data warehousing platform, often preferred over Cosmos DB for pure relational warehousing.
3. Integration Ecosystem (Stage 5)
Azure's Power BI offers unparalleled integration with the wider Microsoft ecosystem (Excel, Teams, etc.).
GCP Data Studio is designed for easy connection to all Google services, including Sheets and Ads data.
AWS QuickSight is rapidly developing, providing integrated dashboards within the AWS environment.
No matter which cloud you choose, optimizing your data pipeline involves minimizing resource overhead and maximizing query speed. This cheatsheet is your starting point.
Ready to architect your next multi-cloud Big Data solution? YA INNOVATION LAB specializes in cloud-agnostic data engineering and pipeline optimization. Contact us today to review your current architecture and identify critical cost savings!

